摘要
作者提出了一种新的物体检测方法YOLO。YOLO之前的物体检测方法主要是通过region proposal产生大量的可能包含待检测物体的 potential bounding box,再用分类器去判断每个 bounding box里是否包含有物体,以及物体所属类别的 probability或者 confidence,如R-CNN,Fast-R-CNN,Faster-R-CNN等。
YOLO不同于这些物体检测方法,它将物体检测任务当做一个regression问题来处理,使用一个神经网络,直接从一整张图像来预测出bounding box 的坐标、box中包含物体的置信度和物体的probabilities。因为YOLO的物体检测流程是在一个神经网络里完成的,所以可以end to end来优化物体检测性能。YOLO检测物体的速度很快,标准版本的YOLO在Titan X 的 GPU 上能达到45 FPS。网络较小的版本Fast YOLO在保持mAP是之前的其他实时物体检测器的两倍的同时,检测速度可以达到155 FPS。相较于其他的state-of-the-art 物体检测系统,YOLO在物体定位时更容易出错,但是在背景上预测出不存在的物体(false positives)的情况会少一些。而且,YOLO比DPM、R-CNN等物体检测系统能够学到更加抽象的物体的特征,这使得YOLO可以从真实图像领域迁移到其他领域,如艺术。
核心思想
- 整张图作为网络的输入,把 Object Detection(物体检测)问题转化成一个Regression(回归)问题,用一个卷积神经网络结构直接在输出层回归bounding box的位置和bounding box所属的类别。
- Faster RCNN中也直接用整张图作为输入,但是faster-RCNN整体还是采用了RCNN那种proposal+classifier的思想,只不过是将提取proposal的步骤放在CNN中实现了。
算法特点
- 将物体检测作为回归问题求解。基于一个单独的End-To-End网络,完成从原始图像的输入到物体位置和类别的输出,输入图像经过一次Inference,便能得到图像中所有物体的位置和其所属类别及相应的置信概率。
- YOLO网络借鉴了GoogLeNet分类网络结构。不同的是,YOLO未使用Inception Module,而是使用1x1卷积层(此处1x1卷积层的存在是为了跨通道信息整合)+3x3卷积层简单替代。
- Fast YOLO使用9个卷积层代替YOLO的24个,网络速度更快,在Titan X GPU上的速度是45 fps(frames per second),加速版的YOLO差不多是155fps。但同时损失了检测准确率。
- 使用全图作为 Context 信息,这一点和基于sliding window以及region proposal等检测算法不一样。与Fast RCNN相比,误检测率(把背景错认为物体)降低一半多。
- 泛化能力强,可以学到物体的generalizable representations,在自然图像上训练好的结果在艺术作品中的依然具有很好的效果。
优缺点
YOLO模型相对于之前的物体检测方法有多个优点:
1、YOLO检测物体非常快。
因为没有复杂的检测流程,只需要将图像输入到神经网络就可以得到检测结果,YOLO可以非常快的完成物体检测任务。标准版本的YOLO在Titan X 的 GPU 上能达到45 FPS。更快的Fast YOLO检测速度可以达到155 FPS。而且,YOLO的mAP是之前其他实时物体检测系统的两倍以上。2、YOLO可以很好的避免背景错误,产生false positives。
不像其他物体检测系统使用了滑窗或region proposal,分类器只能得到图像的局部信息。YOLO在训练和测试时都能够看到一整张图像的信息,因此YOLO在检测物体时能很好的利用上下文信息,从而不容易在背景上预测出错误的物体信息。和Fast-R-CNN相比,YOLO的背景错误不到Fast-R-CNN的一半。3、YOLO可以学到物体的泛化特征。
当YOLO在自然图像上做训练,在艺术作品上做测试时,YOLO表现的性能比DPM、R-CNN等之前的物体检测系统要好很多。因为YOLO可以学习到高度泛化的特征,从而迁移到其他领域。尽管YOLO有这些优点,它也有一些缺点:
1、YOLO的物体检测精度低于其他state-of-the-art的物体检测系统。
2、YOLO容易产生物体的定位错误。 3、YOLO对小物体的检测效果不好(尤其是密集的小物体,因为一个栅格只能预测2个物体)。

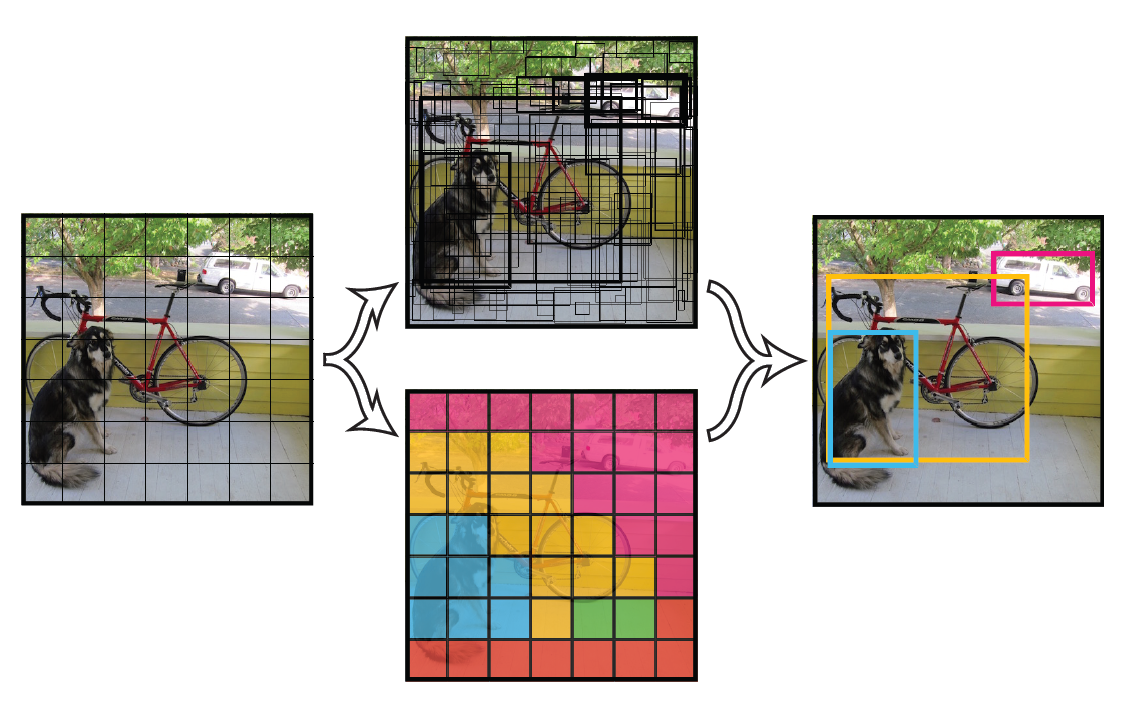




举例说明:在本文中,网络结构参考GooLeNet模型,包含24个卷积层和2个全连接层,卷积层主要用来提取特征,全连接层主要用来预测类别概率和坐标。对于卷积层,主要使用1x1卷积来做channle reduction,然后紧跟3x3卷积。对于卷积层和全连接层,采用Leaky ReLU激活函数,但是最后一层却采用线性激活函数。除了上面这个结构,文章还提出了一个轻量级版本Fast Yolo,其仅使用9个卷积层,并且卷积层中使用更少的卷积核。图像输入为448x448(强制转换),取S=7,B=2,C=20 (因为PASCAL VOC有20个类别),所以最后有 7∗7∗30个tensor。如下图。

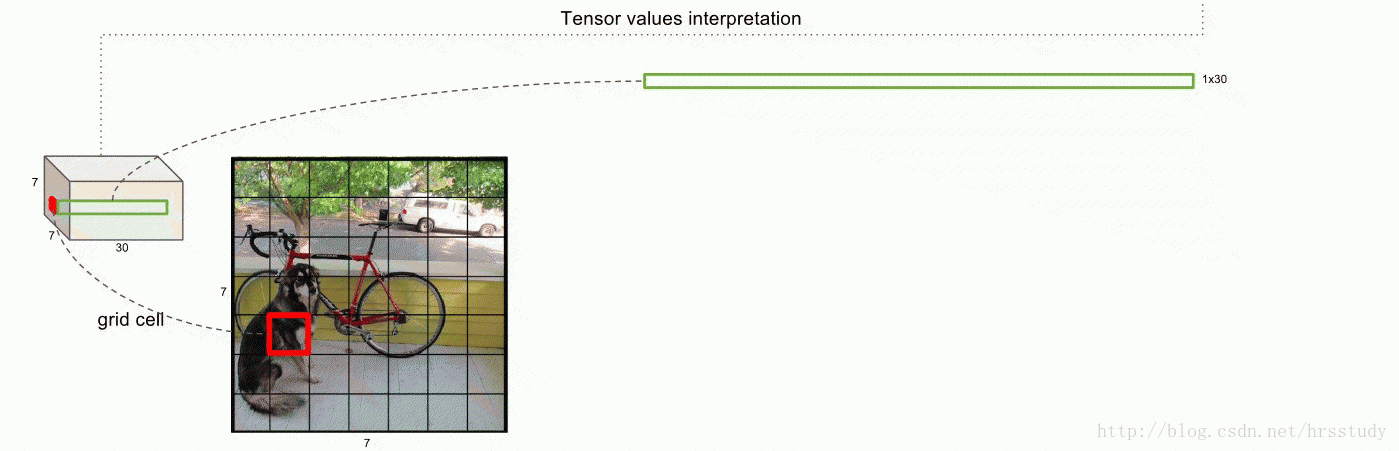
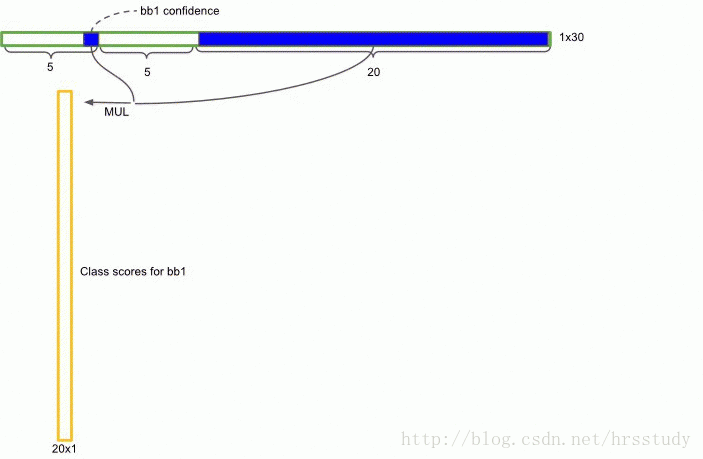
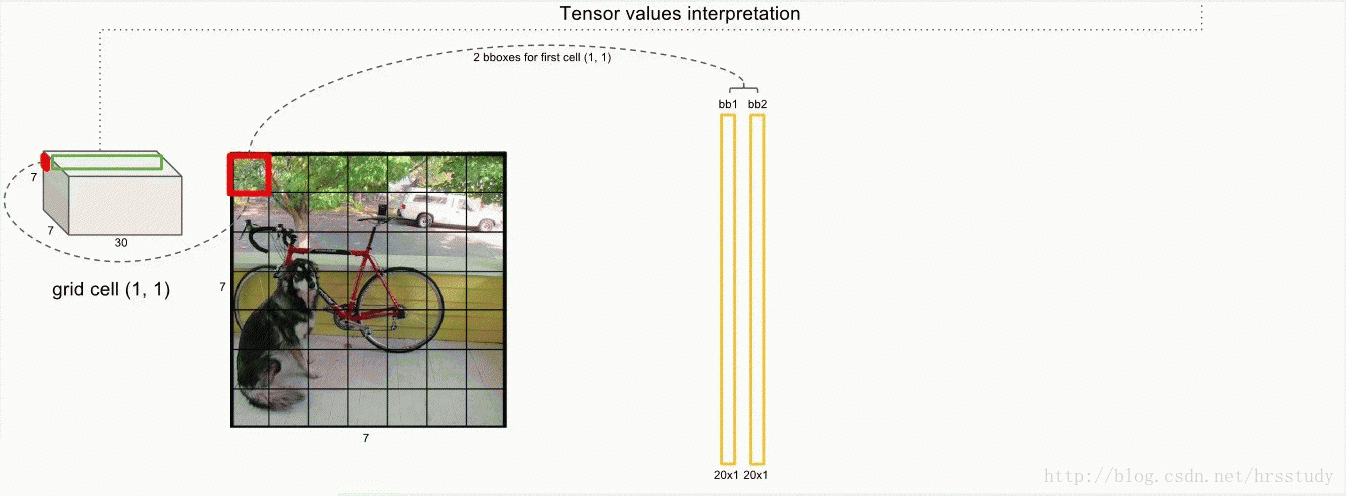
训练

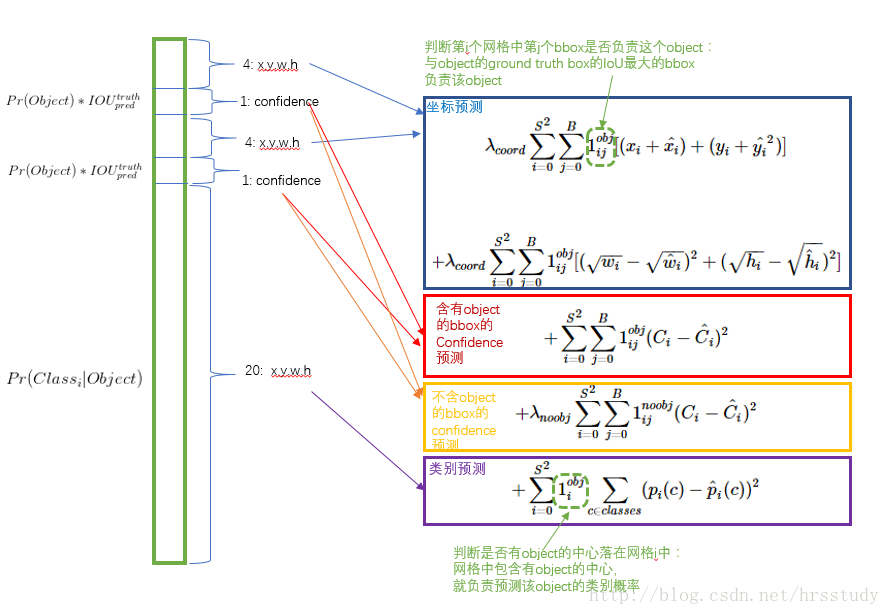

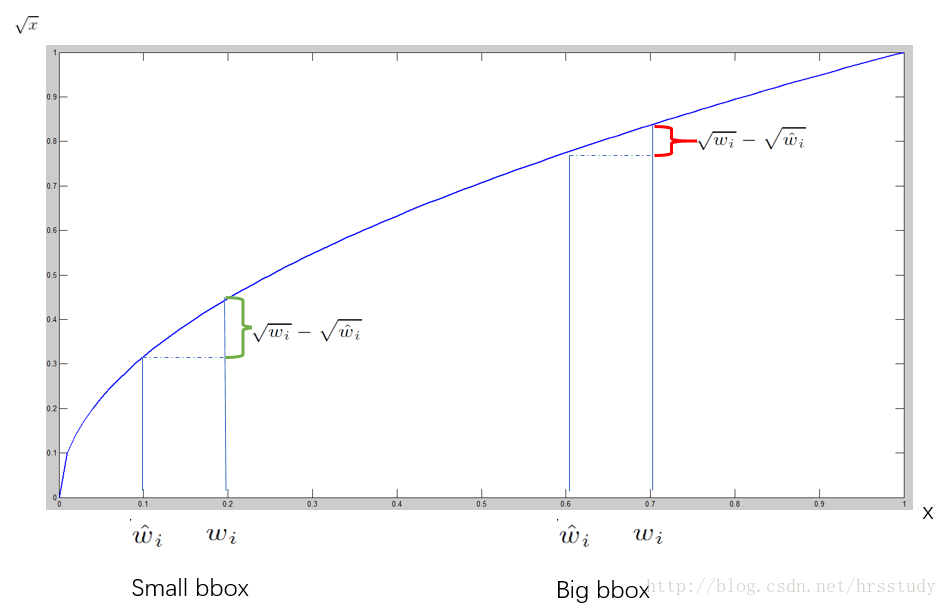


测试

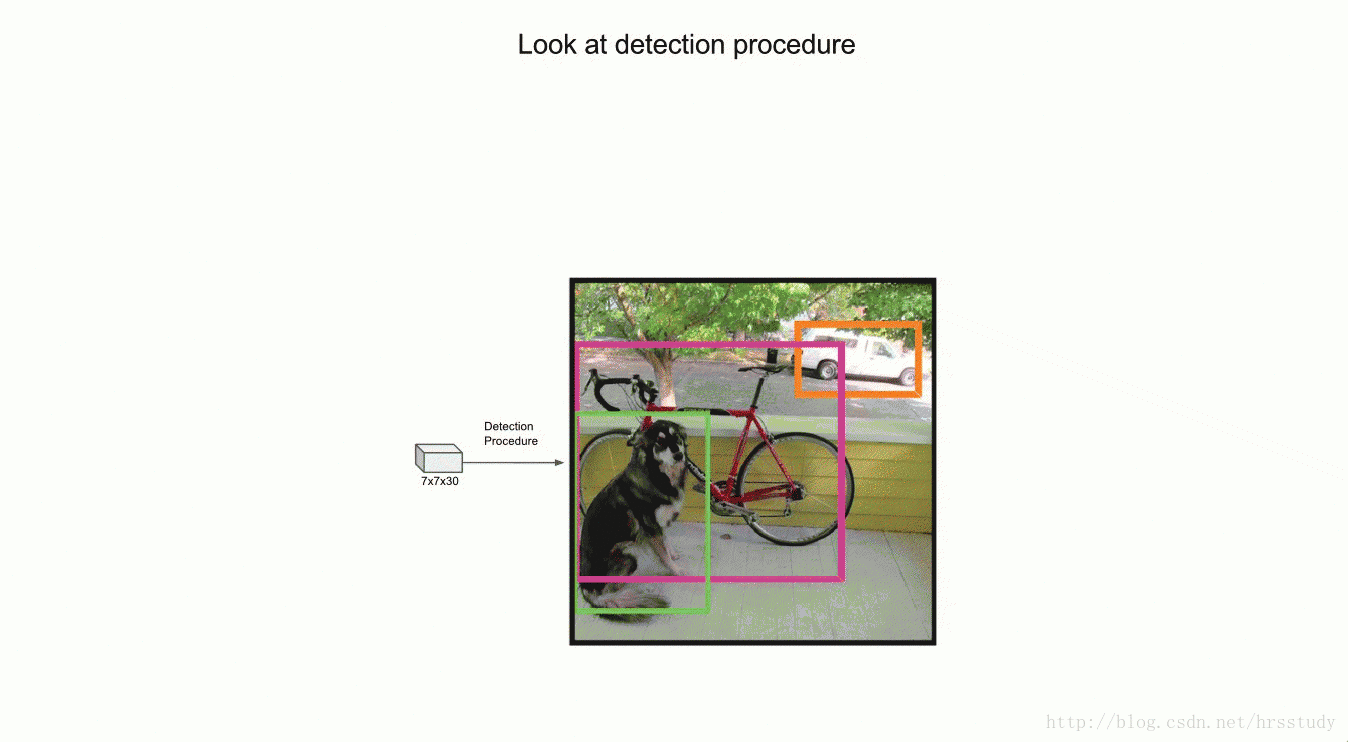
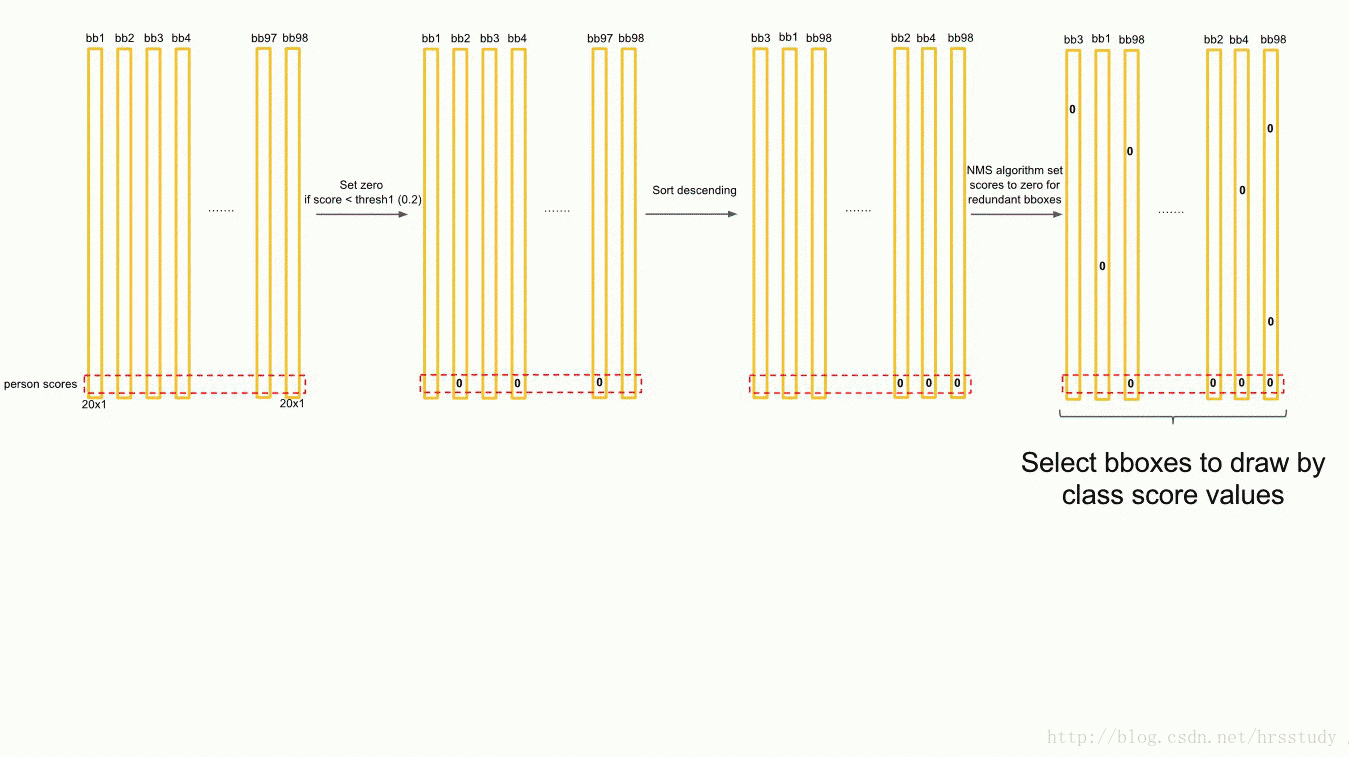
NMS:
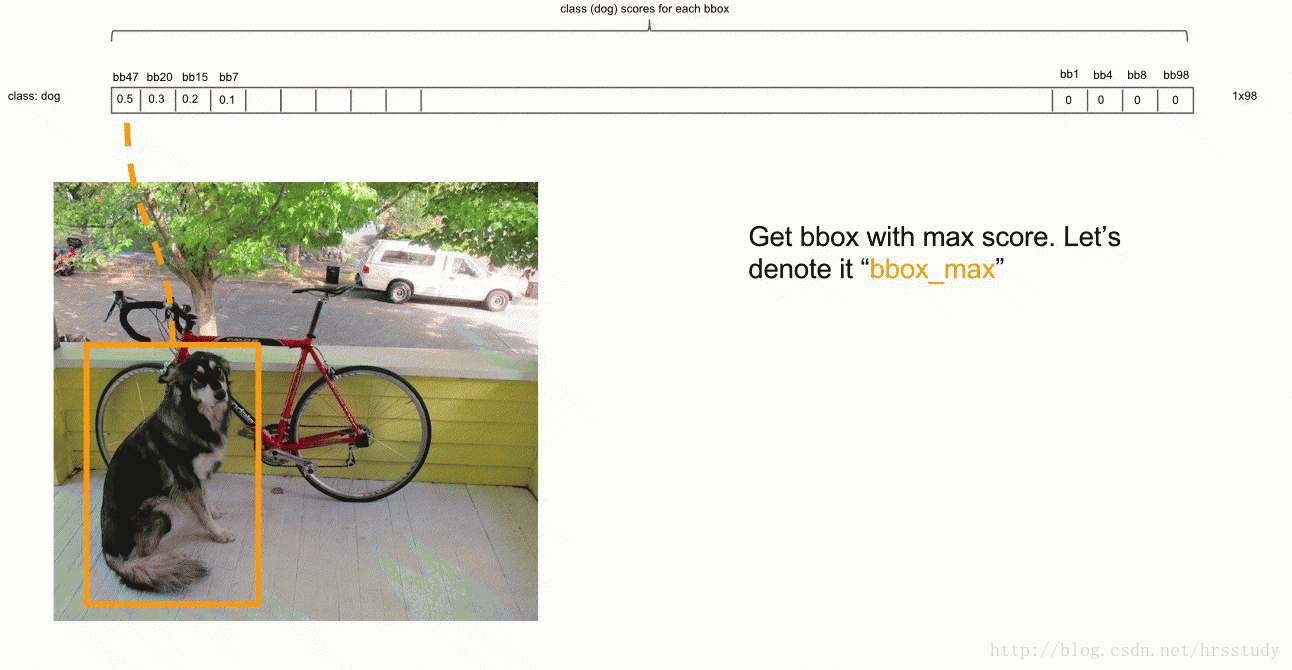
获取目标检测结果:
参考:
https://blog.csdn.net/sunshineski/article/details/83518165